
自定义配置
选择任意服务器和任意GPU。您的服务器采用惠普企业级部件构建,并经过测试,确保与您选择的GPU完全兼容。
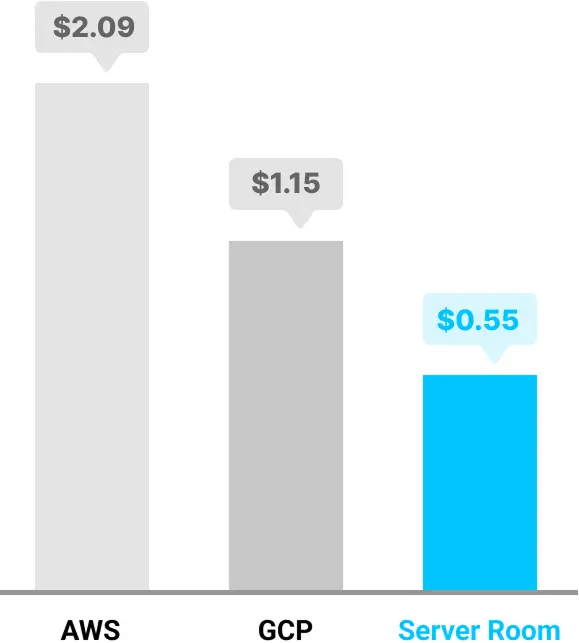
*价格基于配备 40GB 显存的单个 A100 GPU。

NVIDIA 的 Ampere 架构是 Volta 架构的继任者,也是 AI 加速的根本解决方案。NVIDIA A40 为虚拟现实项目、光线追踪渲染等带来了强大的新功能,其第二代 RT 核心性能提升 2 倍,吞吐量空前提高。凭借 336 个 Tensor 核心,AI 应用的训练能力将提升 5 倍,而 GDDR6 显存则支持海量工作负载,足以满足游戏开发者、数据科学家、图形设计师等用户的需求。NVIDIA A100 Tensor Core GPU 是人工智能领域的一项突破性飞跃,它利用 NVIDIA 的多实例 GPU (MIG) 技术,在各种规模下都能提供无与伦比的加速性能。第三代 Tensor 核心的性能提升 20 倍,MIG 技术支持多个网络在单个 A100 GPU 上同时运行,从而最大限度地发挥计算能力。

NVIDIA H100 Tensor Core GPU 代表了人工智能和高性能计算加速的巅峰之作。H100 基于 Hopper 架构,可为大规模 AI 训练和推理工作负载提供前所未有的性能。凭借第四代 Tensor Core 和革命性的 Transformer Engine,H100 可将 AI 模型加速至比上一代产品快 9 倍。多实例 GPU (MIG) 技术等先进特性可将单个 GPU 划分为多个实例,从而实现最佳资源利用率;而 NVLink 和 PCIe Gen5 连接则可确保为要求最苛刻的企业级应用提供最大数据吞吐量。

NVIDIA RTX 6000 Pro 专为满足最苛刻的 3D 工作流程、AI 开发和视觉计算应用需求而设计,提供专业级性能。这款企业级工作站 GPU 配备 48GB 超高速 GDDR6 显存(支持 ECC 纠错)、用于实时光线追踪的先进 RT Core 以及用于 AI 加速计算的强大 Tensor Core。RTX 6000 Pro 专为关键任务型工作负载而打造,在媒体制作、工程仿真、科学可视化和企业级 AI 研究领域表现卓越,能够为大型项目和生产环境提供专业人士所需的可靠性和尖端性能。

NVIDIA L4 和 L40S 数据中心级 GPU 为企业环境中的 AI 推理、视频处理和图形工作负载提供卓越的性能。L4 专为大规模高效部署而设计,在提供出色 AI 推理性能的同时,功耗极低,是边缘部署和视频流应用的理想之选。功能更强大的 L40S 则凭借先进的 Tensor Core 和 RT Core,在 AI 训练、视觉计算和虚拟工作站方面拥有更强大的功能。这两款 GPU 均支持多实例 GPU (MIG) 技术,可实现最佳资源分配,因此非常适合云服务提供商、电信运营商以及运行需要同时进行 AI 推理和图形加速的混合工作负载的企业。

NVIDIA 最新一代 GPU 带来无与伦比的性能,在光线追踪、AI 加速渲染和计算能力方面均实现了突破性进展。这些显卡采用先进架构,兼具卓越的能效和出色的图形处理能力,可满足高要求的工作流程。

NVIDIA GeForce RTX 4090D 为您带来极致的游戏和创作性能体验。这款 GPU 采用革命性的 Ada Lovelace 架构,兼具强大的性能和卓越的能效,可呈现超逼真的画面和身临其境的沉浸式体验。RTX 4090D 拥有先进的光线追踪和 AI 增强功能,即使面对要求最苛刻的游戏和应用程序,也能确保实时呈现电影级渲染效果、流畅的帧速率和顶级性能。
兼容Linux、CUDA/OpenCL、DirectX、Windows。
订单配置
英伟达新一代基于安培架构的GPU性能显著超越了图灵架构的Quadro RTX系列。第二代RT核心可加速照片级渲染、3D设计和光线追踪等工作负载的处理速度,从而实现更高的视觉精度。RTX A系列还将AI技术引入图形处理领域,具备DLSS、AI降噪以及针对特定应用的增强型编辑等功能。

NVIDIA GeForce RTX 30(第二代 RTX)系列 GPU 基于 Ampere 架构,引入了诸多创新技术,从更快的光线追踪和 Tensor Core 到先进的多处理器流式传输,无所不包。其突破性的散热设计(效率提升 2 倍)和超高速 GDDR6X 显存带来卓越的性能,使其成为处理大型数据集的 AI 项目、游戏或可视化应用的理想之选。
兼容Linux、CUDA/OpenCL、KVM、Windows。
订单配置
著名的图灵™芯片架构正在重塑无数视觉创作者和设计师的工作方式。NVIDIA Quadro RTX 系列显卡提供基于人工智能的全新性能、加速光线追踪和高级着色技术,所有这些都将帮助艺术家提升渲染能力。该系列显卡配备 4608 个 CUDA® 核心和 24 GB GDDR6 显存,可支持复杂的视觉设计、8K 视频内容、海量建筑数据集等等。
兼容Linux、CUDA/OpenCL、KVM、Windows。
订单配置
NVIDIA Quadro RTX 4000 系列显卡仅需一个 PCI-e 插槽,即可提供卓越的性能和强大的功能。Turing™ 芯片架构结合现代显示特性和尖端技术,可瞬间呈现逼真的单光线追踪渲染效果。RT 核心实现了这种渲染速度的飞跃,而 Tensor 核心则为各种深度学习应用提供了理想的支持。凭借这一经济高效的解决方案,您现在可以创建逼真的 VR 体验,并在 AI 项目中享受更快的性能。
兼容Linux、CUDA/OpenCL、KVM、Windows。
订单配置
选择 NVIDIA Tesla T4,借助其 Tensor Core 技术,获得强大的多精度计算能力。T4 的速度比传统 CPU 快 40 倍,比其 Pascal 前代产品快 3.5 倍。将 Tesla T4 与我们的 HPE 服务器配置之一搭配使用,即可同时转码多达 38 路全高清视频流。*实际结果可能因服务器配置而异。
兼容系统:VMware ESXi、Citrix Xenserver、KVM、Linux、Windows。
订单配置
Coral USB加速器
借助全新的 Coral USB 加速器,您可以将 Edge TPU 添加到任何基于 Linux 的系统中。它功耗低,却能提供高性能的机器学习。
兼容 Linux 机器、Debian 6.0 或更高版本,或任何衍生版本(如 Ubuntu 10.0+),也兼容 Raspberry Pi(213 模式 B/B+)。

RTX 2080 采用 NVIDIA 全新的 Turing 芯片架构,性能最高可达 Pascal 芯片前代产品的六倍。
兼容Linux、CUDA/OpenCL、KVM。
订单配置
采用 NVIDIA Pascal 架构的 GPU——GeForce GTX 1070/1080,可在图形渲染、计算或挖矿方面获得卓越的性能。
兼容Linux、CUDA/OpenCL、KVM。
订单配置
NVIDIA Tesla P4 和 P100 GPU 是机器学习和视频转码的理想之选。NVIDIA 的 Pascal 架构芯片已被证实比其前代 Maxwell 架构速度更快、能效更高。只需一块 Tesla P4 GPU 搭配我们的 HPE BL460c 刀片服务器,即可同时转码多达 20 路视频流。* Tesla P40 是 Tesla P4 的升级版,其处理能力是 Tesla P4 的两倍以上。Tesla P100 GPU 最适合深度学习和远程图形处理。凭借 18.7 TeraFLOPS 的推理性能,一块 Tesla P100 GPU 即可替代超过 25 台 CPU 服务器。*实际结果可能因服务器配置和各视频流的分辨率而异。
兼容系统:VMware ESXi、Citrix Xenserver、KVM、Linux、Windows。
订单配置
与 P100 GPU 板相比,深度学习速度最高可提升 1.5 倍。Titan V GPU 的推理性能高达 110 TeraFLOPS。您可以使用 Titan V 来预测天气或探索新的能源。它是实现精准快速结果的理想 GPU 选择。一台 Titan V GPU 服务器最多可替代 30 台单 CPU 服务器。实际结果可能因服务器配置而异。
兼容系统:VMware ESXi、Citrix Xenserver、KVM、Linux、Windows。
订单配置您的资源密集型应用需要企业级硬件,并经过压力测试以应对持续高负载。您的GPU专用服务器配置将经过一系列测试,以确保与您选择的GPU完全兼容并集成。您的服务享有99.9%的正常运行时间SLA保障,并由专家团队提供全天候支持。